 admin
adminСпособ далеко не самый лучший, но простой, и бывает довольно результативным – иногда позволяет выцепить важные синонимы с малыми усилиями.
Смысл синонимов
Тут всё очевидно – имея нужные базовые фразы, можно их распарсить как угодно (и/или дополнить выгрузкой из Букварикса), то есть, закладываем фундамент более качественной проработки семантики.
Исходные данные
Есть некая базовая фраза (называемая в некоторых кругах «маркерный запрос» или «маркер»), от которой отталкиваемся при сборе семантики. При этом, она может быть не основной (не самым высокочастотным синонимом).
Основное условие – базовая фраза не должна быть от балды, и по выдаче должно быть видно (например, здесь), что она «наша» (подходящая).
Непосредственно способ
- Парсинг базовой фразы против правой колонки Yandex Wordstat, Google Ads, похожих запросов, подсказок Директа;
- Удаление неявных дублей;
- Съём поисковой выдачи для подобранного;
- Группировка («кластеризация») в режиме hard 2 с базовой фразой в качестве «маркера».
Если без софта
Если работаем без софта (КК и кластеризатор), а только с помощью онлайн сервисов, тогда:
- То же самое, только ограничиться Гугл Эдс и Правой колонкой https://wordstat.yandex.ru/ (может оказаться полезным расширение https://semantica.in/tools/yandex-wordstat-assistant);
- Используем онлайн-кластеризатор, например, http://coolakov.ru/tools/razbivka/ – смотрим, в какие группы ушли базовые фразы, и работаем с этими группами.
Парсинг
Базовые фразы для примера:
- ремонт турбин;
- аудит пожарной безопасности;
- рекламные туры;
- невропатия лицевого нерва.
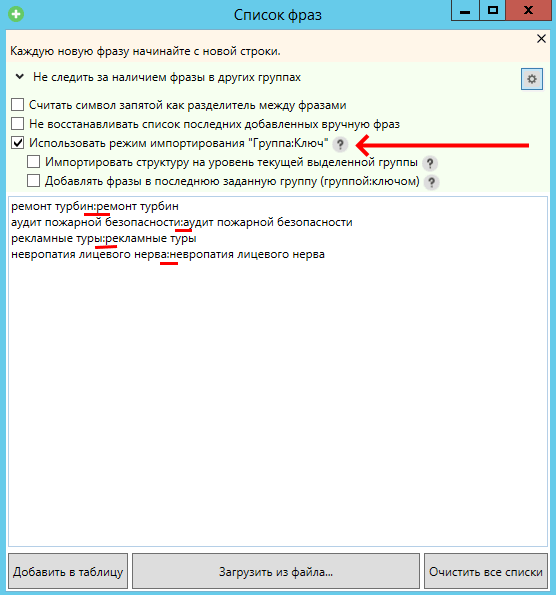
Далее рассматриваю работу через Key Collector 3-й. Итак, закидываем в КК, например, так:
Затем парсим Эдс («широкий» регион – Россия, галки фильтрации вариантов сняты):
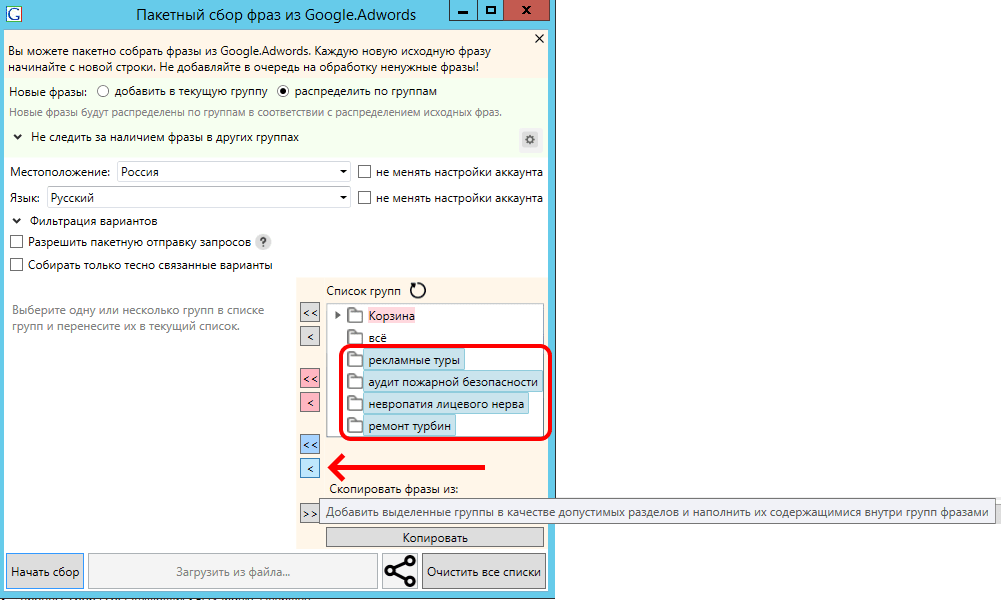
По аналогии парсим Правую колонку, также выставив «широкий» регион (Россия), похожие запросы, подсказки Директ.
Удаление неявных
Включаем режим мультигруппы для всех проработанных групп и фильтруем по источнику «добавлено вручную», и в колонку комментарий что-нибудь вписываем, например:
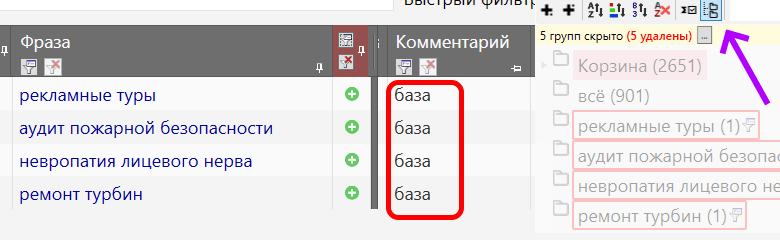
Фильтруем по отрицанию комментария: не содержит «база» (без кавычек) – если как в примере.
Выполняем поиск неявных с такими настройками:

Удаляем неявные. Очищаем фильтр.
Съём поисковой выдачи
Выставляем нужный регион (в примере был выставлен СПб), снимаем выдачу. Удобно с https://xmlproxy.ru/ (ставка 5 р./1000 запросов).
Если используется кластеризатор семантики, который поддерживает работу с «маркерными запросами» и сам снимает выдачу (например, KeyAssort), тогда этот шаг можно пропустить.
Группировка фраз
Выставляем в кластеризаторе hard-2 в качестве силы группировки и группируем («кластеризуем») все фразы по нашим «маркерам» (4 базовые фразы из примера).
В примерах группировка проведена кластеризатором Altblog (не бесплатной версией).
Результаты
По рекламным турам бросается в глаза слово «рекламники», поэтому возьмём его на проверку (забегая вперёд – да, это синоним), а также неплохо проверить и что за рекламный туроператор:

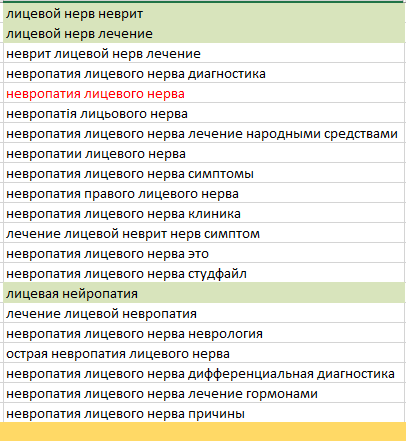
Для болезни заметны слова «неврит», «нейропатия», «лицевая», и требует проверки также слово «лечение» - возможно, эта под-тема должна раскрываться на той же странице для закрытия намерения пользователя (так называемый «интент»), и фразу «лицевой нерв лечение» возможно также нужно взять в работу:
Для аудита напрашивается на проверку фраза «пожарный аудит» (независимый можно не брать, т.к. это всё выйдет при хорошем распарсе просто пожарного, если он подойдёт):

Для ремонта обращают на себя внимания слова «восстановление» и «отремонтировать», слово «турбокомпрессор» требует проверки (предположим, что мы не знаем, тот же ли это агрегат), и интересна фраза с Питером – возможно, поиск понимает по навигационному слову, что юзер имеет то же намерение, что и юзер, вбивающий «ремонт» (а может намерением является покупка новой? – надо проверить, вообщем):

Всё ?
Типа да. То есть, не особо заморачиваясь получили интересные данные, которые можем проверить по выдаче, и если подходят, то составить итоговые фразы на парсинг.
Справедливости ради, иногда по синонимам получается совсем скудный урожай (тогда, когда они есть).
Расширение подхода
То есть, по опыту, как бы не тюнинговать методу, качество результата будет не сильно лучше (если будет лучше вообще), а времени и усилий уйдёт (значительно) больше.
Примеры тюнинга:
- закидывать на парсинг не одну фразу, а несколько из одной недоработанной группы («кластера») – например, распарсить базовую в левой колонке Вордстата, снять выдачу и сгруппировать с силой хард-3, и всё, что уйдёт в одну группу с базовой, закинуть на поиск синонимов;
- можно попробовать спарсить и Руки (давно это не делал, т.к. приплывало много мусора, но бывало, находилось интересное);
- исследовать и прочие условно-тематические «кластеры», пробовать разные силы группировки.