Frog eTXT helper -- утилита, работающая в связке со Screaming Frog Seo Spider (Лягушка) и программой для ПК Etxt. Лягушка - для парсинга текста, Etxt - непосредственно для проверки на уникальность, а Фех - своего рода связующее звено.
Работа с утилитой
Текст парсится Лягушкой с помощью экстракторов, затем из CSV экспорта экстракторов Лягушки Фехом выдирается текст и распиливается на файлы (1 файл = 1 url сайта с текстом), которые потом проверяются на уникальность с помощью Etxt с сохранением отчёта в файлы, после чего с помощью Феха делается отчёт.
Парсинг текста с сайта
Нужно настроить экстракторы Лягушки и спарсить интересующие текстовые фрагменты страниц, которые и формируют "текст" страниц.
Допустим, спарсили тексты сайта с такими экстракторами (текст над витриной каталога и текст под ней):
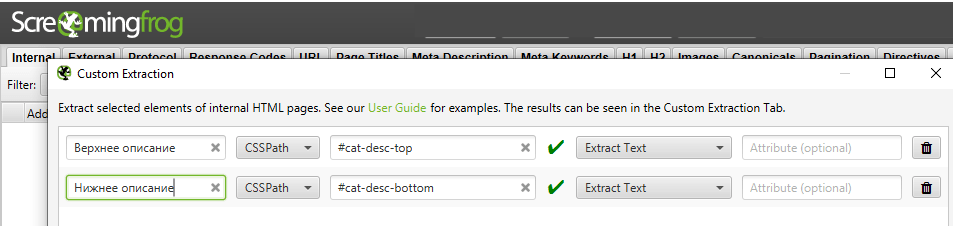
Экспортируем со вкладки "Custom Extraction" в CSV (после нажатия "Export" в появившемся диалоговом окне выбираем "Coma Separated Values (*.csv)"):

Распиливание CSV на части
Запускаем Фех, выбираем режим "Разрезание на файлы". В поле "экстракторы Лягушки" удобнее всего вбивать порядковые номера экстракторов -- как они идут в интерфейсе Лягушки (считать номера экстракторов самостоятельно, сверху вниз). Но можно использовать и названия экстракторов.
Итак, в нашем примере (с верхним и нижним описанием) вбиваем "1,2" (без кавычек):
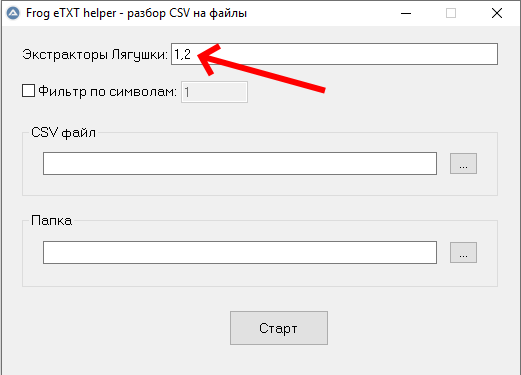
Ставим чекбокс "фильтр по символам" и задаём число символов -- если необходимо отсеять проверку уникальности текстов по числу символов с пробелами. Например, на ряде url'ов у нас слишком коротенькие тексточки, которые не хотим проверять на уникальность.
Выбираем наш файл CSV, пустую (!) папку, куда будут сохранены файлы и нажимаем "старт", и ждём завершения работы утилиты.
div.text-fragment
И на целевых страницах (откуда парсится текст) есть несколько блоков с классом text-fragment. В таком случае у нас в экспорте экстракторов в первой строке будет примерно следующее:
"Address","Status Code","Status","text fragment 1 1","text fragment 1 2","text fragment 1 3"
Фех корректно распознает, что все 3 элемента относятся к экстрактору "text fragment".
Также, будет файл-словарь для соотнесения имён файлов и url'ов. Это понадобится далее.
Проверка уникальности обычная
Запускаем Etxt, настраиваем как нужно (в частности, неплохо исключить сайт, с которого спарсили тексты), и вот это надо задать на вкладке "отчёт":
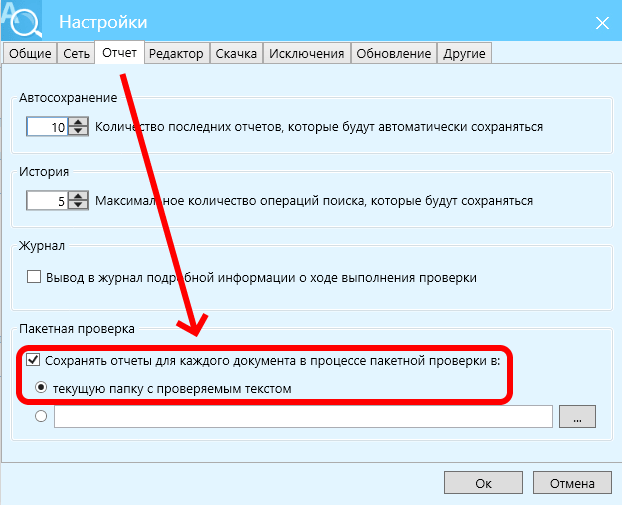
Далее в главном меню Etxt выбираем "операции" -> "пакетная проверка", указываем папку, где сохранены были наши файлы при распиле CSV, выставляем прочие настройки при необходимости. Запускаем проверку на уникальность и ждём её завершения.
Формирование отчёта по уникальности
Запускаем Фех, выбираем режим "Формирование отчёта". Выбираем папку с нашими файликами (теперь она содержит и *.html файлы с данными по уникальности текстов) и нажимаем "старт".
В результате будет сформирован файл index.html в папке с файликами. Открыв его увидим нечто вроде такого:

Можно сортировать таблицу по любой колонке, экспортировать в Эксель, скопировать. Также, url'ы кликабельны, и ведут на соответствующие результаты проверки Etxt, включая подсветку неуникальных кусков текста, на каких url'ах в интернете найдены копии/частичные копии.
Проверка уникальности только в рамках сайта
Если проверяем уникальность текстов по сайту, то всё то же самое, что и для обычной проверки, только выбираем "операции" -> "пакетная проверка" -> "локальная проверка":
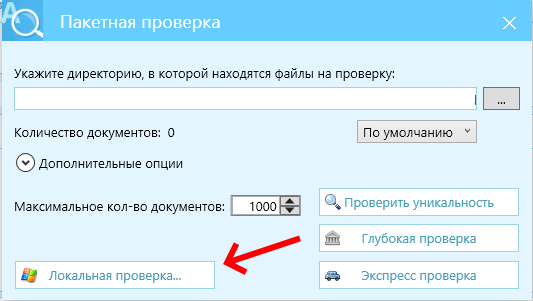
Единственное, результат локальной проверки после формирования отчёта Фехом будет мало пригоден -- в деталях проверки (когда кликнуть на url в отчёте) будут указаны имена файлов, где есть дублирование, а не url'ы. Разве что для общей прикидки, на каких url'ах на сайте дублируется текст (тем более, это быстро и нет расходов на антикапчу).
Хорошо бы мне довести до ума, но как-то лениво.
Приостановка и возобновление работы Etxt
Работу Etxt можно в любой момент приостановить. Чтобы продолжить с места остановки, не теряя прогресс проверки, надо запустить Фех и выбрать режим "Отсев отработанного", установить радиобатон в положение "Последний" и нажать "старт":
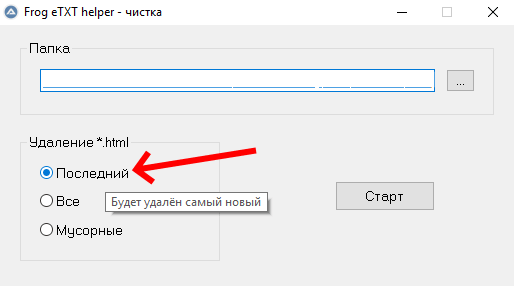
Также, полностью отработанные (проверенные на уникальность) текстовые файлики упаковываются в архив, чтобы исключить их повторную обработку с помощью Etxt при возобновлении проверки.
Достоинства
- Помогает недорого (расходы на антикапчу) и массово производить проверку текстов на уникальность;
- Возможность проверять произвольные тексты, приведя их к виду CSV экстракторов Лягушки (число колонок и разделение элементов);
- И вообще, данный раздел здесь потому, что есть раздел недостатков.
Недостатки
- Возможно наличие (гораздо) более лучших альтернатив на рынке;
- Знание CSS-селекторов и/или Xpath -- чтобы парсить тексты Лягушкой;
- Долго ждать окончания работы Etxt, если текстов (url'ов) много;
- Кривоватый отчёт для локальной проверки;
- Необходимость подключения к интернету для скачивания компонентов для формирования отчёта (да, тут тоже кривовато сделал, но благо, что постоянный интернет на ПК сейчас есть практически у всех, наверное).
Альтернативные решения
Etxt проверка сайта со спец. тегами
У этой программы есть (или была?) фича, которая заключается в том, что можно в HTML коде выделить нужные фрагменты специальными тегами, и Etxt при проверке уникальности вычленяет эти куски текста и проверяет непосредственно их, а не весь текст как происходит при обычной проверке сайта. Вроде бы так.
Находил я в ветке на Searchengines соответствующую инфу от разработчика (?), но, увы, не сохранил, а сейчас не могу найти.
Если есть возможность массово расставить нужные теги на сайте, то этот вариант может быть лучше костылей вроде Феха. Однако, уникальность по сайту таким способом может и нельзя проверить, но не утверждаю, т.к. не разобрался.