 admin
adminИногда полезно выяснить, чего не хватает в структуре сайта (далее – нашего сайта), либо по каким кластерам нет видимости/недостаточная видимость, хотя на нашем сайте есть соответствующие посадки. Здесь рассмотрю один из (целого ряда) способов, основанных на видимости сайтов-конкурентов.
Смысл простой – выявить и проверить фразы, по которым конкуренты имеют видимость, но наш сайт не имеет. Мы не стремимся данным способом дополнить семантику, а всего лишь получить данные, куда расширяться по структуре.
- Подписка Keys.so
- Видимость сайта
- KeyCollector и сервис XML запросов
- Определение сайтов-конкурентов
- Выгрузка фраз конкурентов
- Программа Penguin
- Объединение и чистка фраз
- Кластеризация/группировка
- Итоговые данные
1. Подписка Keys.so
Нужен доступ к сервису Keys.so – подписка с хорошим потолком строк в отчётах, например, «Профессионал». Хотя, если видимость нашего сайта и конкурентов не столь высокая (ниша не широкая), должна подойти и «Базовая».
2. Видимость сайта по данным Keys.so
Отправная точка – фразы нашего сайта – для последующего сравнения с фразами конкурентов и выявления отсутствующих.
Выгружаем через сервис Keys.so ключевые фразы сайта. На главной странице результатов для проверяемого сайта ищем подзаголовок «Ключевые фразы» и нажимаем «Открыть все», попадаем на страницу запросов, например:
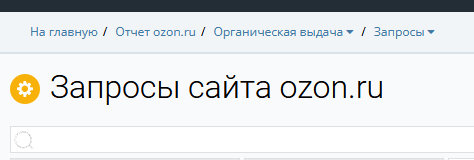
2.1. Фильтрация выборки
Настраиваем фильтры Keys.so, чтобы сузить число фраз, но так, чтобы потеря качества выборки была несущественной. Пример финального вида фильтров:
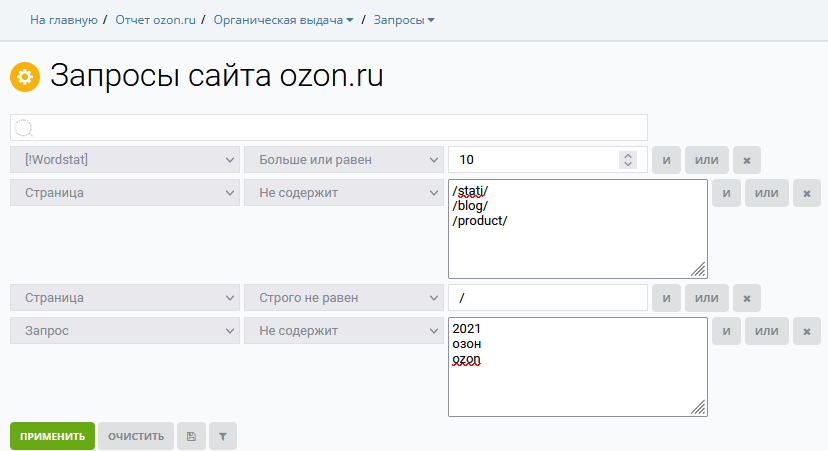
2.1.1. Очень точная частота
Нам нужно взять все основные сайты конкурентов. Для этого не нужны все фразы, и можно отсечь по какому-то значению* очень точной частоты – всё равно выявим всех основных конкурентов.
* подбираем навскидку, в зависимости от ниши;
Для сравнения с конкурентами, нам также будет достаточно фраз, за минусом менее значимых – опять же, мы не расширяем семантику, а выявляем недостающие в структуре кластеры, на которые укажут оставшиеся фразы (более значимые).
2.1.2. Брендовые и мусорные фразы
Исключаем брендовые/витальные фразы (если они есть) – те, которые чётко указывают, что юзер ищет что-то именно на нашем сайте.
Также, навскидку отсеиваем явный мусор по вхождению мусорного слова в фразу.
2.1.3. Главная страница
Для порталов/магазинов/агрегаторов и тому подобного, фразы, по которым видима главная страница нашего сайта, не имеют ценности для оценки структуры, поэтому исключаем главную страницу.
2.1.4. Неинтересные иерархии
Если мы работаем над категорийной структурой, то нам неинтересны продуктовые страницы, раздел блога и прочее подобное. Отсекаем все соответствующие фразы фильтром по вхождению фрагмента иерархии в url (см. пример выше).
2.1.5. Прочие фильтры
Вышеприведённые фильтры отсекут основное ненужное, но, разумеется, набор можно дополнить другими фильтрами, которые помогут ещё сузить выборку без существенной потери её качества.
2.2. Выгрузка в csv
После того, как отфильтровали, скачиваем данные в csv с кодировкой UTF-8.
3. KeyCollector и сервис XML запросов
Нужна программа KeyCollector (3-й или 4-й версии).
3.1. Xmlproxy
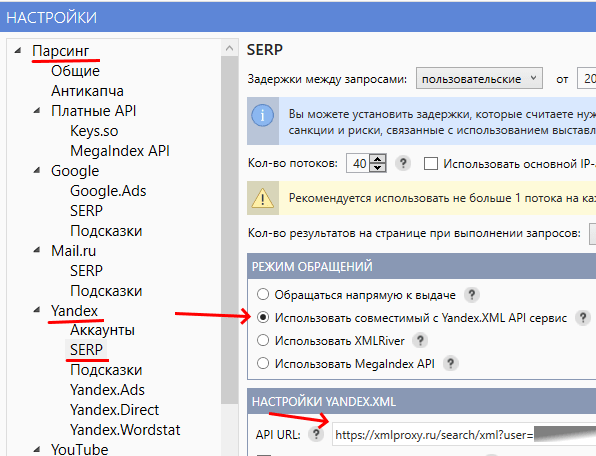
Если работаем по Яндексу, то берём Xmlproxy.ru. В настройках выставляем ставку 5 р./1000 фраз (обычно, этой ставки достаточно).
Настраиваем КК (на примере 4-й версии), указываем url запросов (указан в личном кабинете на Xmlproxy):
3.2. Xmlriver
Если работаем с Гуглом, то тогда затариваемся на этом сервисе. И настраиваем КК соответствующим образом под Xmlriver, а не Xmlproxy.
4. Определение сайтов-конкурентов
Сделаем это следующим образом – снимем поисковую выдачу по ранее подобранным фразам и с помощью этой утилиты получим в наглядном представлении домены сайтов-конкурентов, которые имеют видимость по нашей выборке фраз.
4.1. Съём выдачи и экспорт эксельки
Копируем ранее подобранные фразы (только фразы, прочая статистика на данном этапе не нужна) в Кейколлектор, снимаем поисковую выдачу по продвигаемому региону.
Затем экспортируем с такими установками (для 4-й версии КК):
4.2. Формирование списка доменов и его разбор
С помощью утилиты формируем файл с данными о доменах по инструкции.
Открываем файл и идём по доменам, выбирая близкие к нашему сайту, пропуская неподходящие (информационные, слишком «жирные» и проч. неподходящие). Помощь по работе с таблицей.
В итоге у нас должен получиться список доменов-конкурентов.
4.2.1. Нижний порог – до какого предела пересечений подбирать домены
Необходимо определить некий нижний уровень по пересечению фраз, ниже которого не рассматриваем домены.
Например, у нас 12 980 фраз. 1% это 130 пересечений для домена. Решили, что берём все домены, вплоть до 3% пересечений. Это значит, что домены с менее 390 пересечений (130 * 3), не рассматриваем. Такой домен в данном случае подходит (600 > 390):
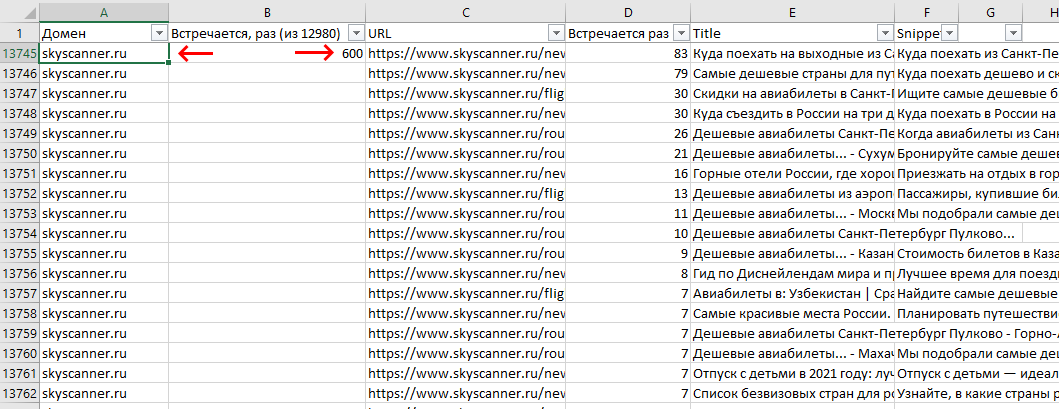
Вообще, безопасным должен быть уровень в 2% пересечений – получим в итоге подавляющее большинство нужных фраз, не перелопачивая все домены (слишком долго).
5. Выгрузка фраз конкурентов из Keys.so
Выгружаем из Keys.so фразы по каждому домену с фильтрами.
5.1. Фильтры
После настройки удобно сохранить в наборы фильтров, потому что каждый раз придётся выставлять – доменов могут быть десятки.
5.1.1. Очень точная частота
То же значение, которое использовали при выгрузке фраз для нашего сайта. Для однозначности и более корректных результатов.
5.1.2. Позиция в блоке
Выставляем границу (вхождение в топ 10/15). Тут можно потерять часть полезных фраз – на сайте-конкуренте может быть охвачен структурный кластер, но иметь плохую видимость, и отсекая по топу, мы отсекаем этот кластер.
Однако, это видится допустимым и необходимым:
- Засчёт широкого охвата доменов-конкурентов, упущенные фразы для одних доменов должны в итоге где-то всплыть для других доменов (у которых нормальная видимость по этим фразам);
- Нам нужно ограничить выборку, чтобы не перелопачивать потом десятки тысяч фраз, плюс, чем дальше от топа, тем выше вероятность, что кластер/фраза нецелевая для домена и тематики.
5.2. Групповой отчёт Keys.so
Как правило, не подходит, потому что там ограничение по числу строк в отчёте, которое при мало-мальски хорошем количестве фраз, отрезает многие из них, и тогда в итоге получается плохой результат.
Поэтому, руками вбиваем и скачиваем выгрузку по каждому домену – по аналогии как делали для нашего сайта, только с другой фильтрацией.
6. Программа Penguin
Далее будет использоваться программа Пингвин версии Keywords Tools. Однако, скорее всего, большинство или все рассматриваемые операции можно выполнить без этого софта (Notepad++, Excel, КК).
7. Объединение и чистка фраз конкурентов
Для сравнения с фразами нашего сайта, нам нужно объединить и почистить выборку фраз конкурентов.
7.1. Убирание дублей и первоначальная чистка
Сначала сделаем следующее – уберём дубли фраз, плюс оставим только те, которые встречаются минимум на двух доменах. Это может отсечь полезные фразы, однако, опять же, это и необходимо, и допустимо:
- Засчёт широкого охвата конкурентов, все нужные фразы у нас всё равно должны пройти; маловероятно, что нужный нам структурный кластер есть только у одного сайта-конкурента;
- Оставив уникальные фразы для домена, пришлось бы перелопачивать десятки тысяч фраз конкурентов с высокой долей вероятности их отбраковки в итоге;
Итак, открываем все скачанные на шаге 5 файлы в Пингвине (выбираем один из двух способов):

7.1.1. Удаление ненужных столбцов
Оставим только те данные, которые потом пригодятся, поэтому, мои кандидаты столбцов на удаление следующие:
- Страница;
- Позиция;
- Эффективность ключевого слова;
- Количество слов в запросе;
- Количество объявлений;
- Документов найдено;
- Число колдунщиков;
- Новый запрос;
- Изменение позиции;
- Смена URL;
- Дата выдачи.
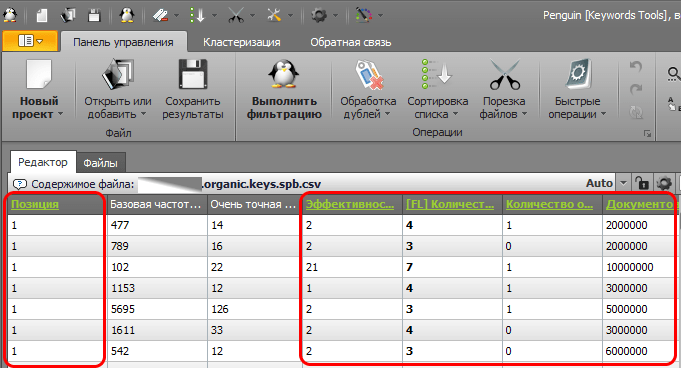
Щёлкаем в Пингвине на названии каждого столбца с зажатой клавишей ctrl. В итоге, зелёный цвет заголовка столбца будет свидетельствовать о том, что столбец выделен:
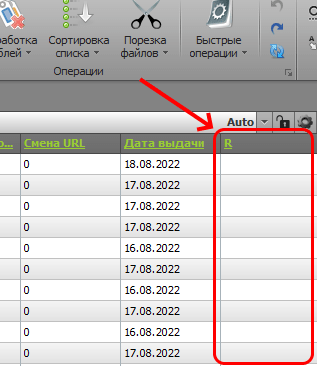
Если есть последний пустой столбец, его также выделяем:
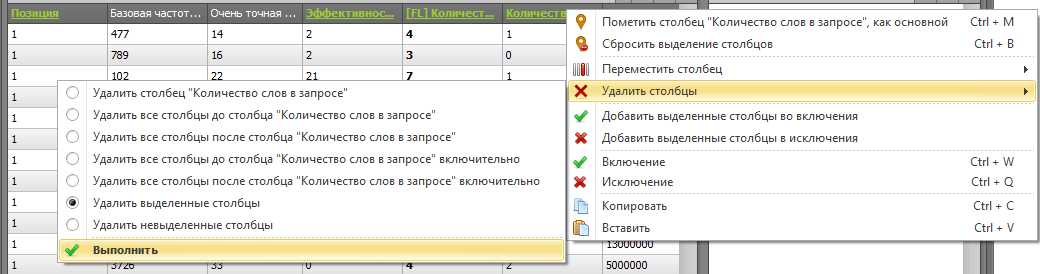
Щелкаем правой кнопкой мыши на строке заголовков и через контекстное меню удаляем выделенные столбцы:
7.1.2. Удаление дублей и подсчёт количества встречаний каждой фразы
Активируем колонку «Запрос» - нажимаем на её заголовок, чтобы он стал оранжевого цвета (индикатор активации колонки).
Выбираем через раздел обработки дублей пункт «Найти явно дублирующиеся строки»:
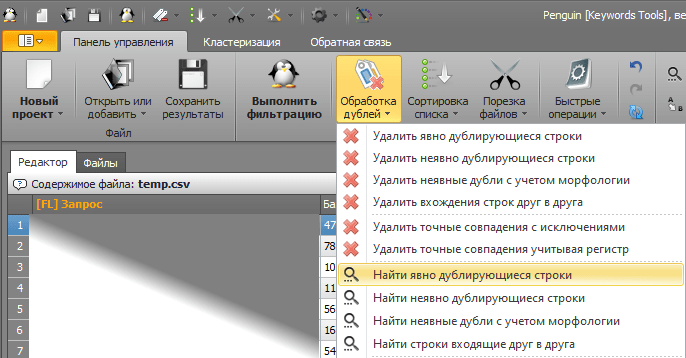
Эта операция удалит дубли и добавит новую колонку «Повторы», в которой будет указано, сколько раз встречается фраза в списке – в нашем случае, на скольких доменах встречается фраза.
7.1.3. Удаление фраз, встречающихся на одном домене
Выделяем новую колонку «Повторы», в блоке «Исключения» вписываем =1 и нажимаем кнопку «Выполнить фильтрацию»:
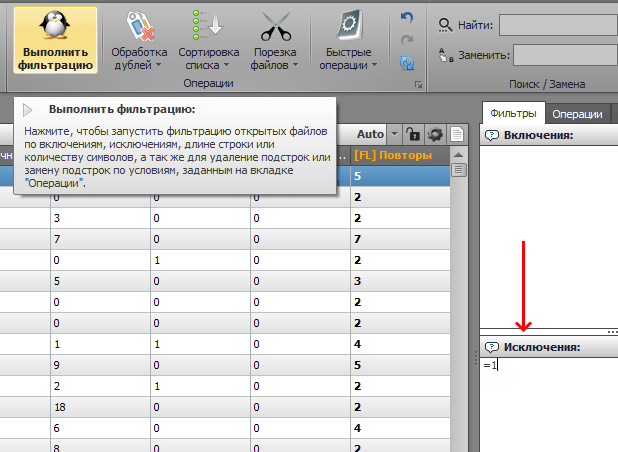
7.1.4. Дальнейшая чистка и экспорт в csv
Удаляем колонку «Повторы»:

Также, можно почистить выборку, поработав со столбцом «Является вопросом» - по аналогии с манипуляциями на шаге 7.1.3, а затем удалив этот столбец, как мы ранее удалили столбец повторов.
После всех манипуляций, экспортируем в csv – кнопка «Сохранить результаты».
7.2. Отсев общих фраз
Сравним фразы, выгруженные для нашего сайта, с фразами конкурентов, и уберём общие (основная цель наших мероприятий).
Сделаем это с помощью функции Эксели ВПР (VLOOKUP). Можно было бы использовать любой онлайн сервис по сравнению списков (или эту утилиту), однако, нам нужно сохранить прочую статистику по фразам (прочие колонки).
7.2.1. Импорт csv от Пингвина в Эксель
Нам нужно открыть csv файл в Экселе, и так, чтобы данные были разделены по столбцам. Пингвин сохраняет в csv с запятой в качестве разделителя, и такое у меня открывается в Экселе без разбивки по столбцам.
В таком случае, надо использовать мастер импорта Эксели или эту утилиту (тумблер выставить на замену запятой на точку с запятой и оставить галку учёта кавычек), или через текстовый редактор (например, Notepad++) заменить "," на ";".
Итак, мы в итоге открыли csv в Экселе, и данные разбиты по столбцам как надо.
7.2.2. Фразы нашего сайта
Создаём в открытой на предыдущем шаге эксельке второй лист с произвольным названием, например, «наш домен» и копипастим на него все фразы (исключительно фразы, без других колонок) нашего сайта (экспортированные из Keys.so) в первую колонку.
7.2.3. Вычисления ВПР
Может, есть более подходящая функция (или их комбинация) Эксели для данного шага, но я использую ВПР.
На первом листе (где основные данные) открытой эксельки создаём новую колонку с произвольным названием, например, «наш домен», выделяем ячейку в этой новой колонке на строке 2 и нажимаем кнопку fx:
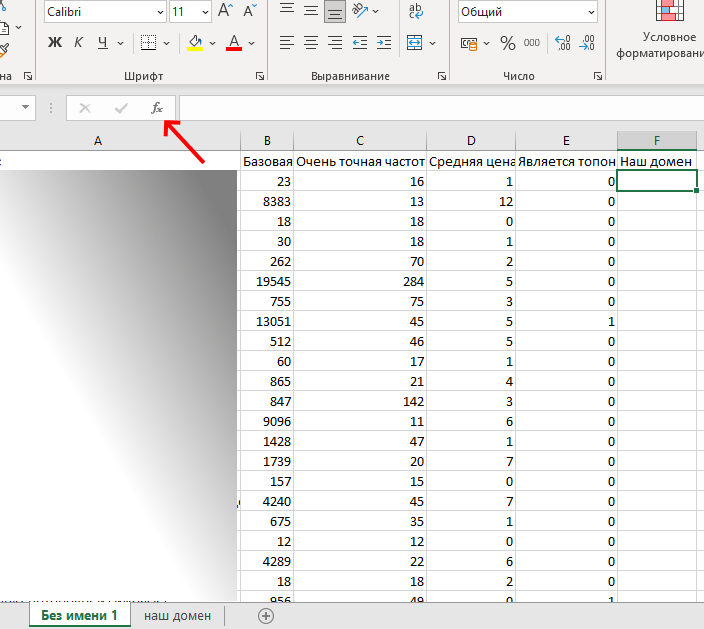
Ищем и выбираем функцию ВПР/VLOOKUP:
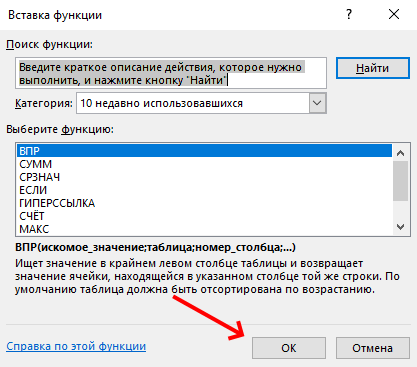
Указываем аргументы функции:

- Искомое_значение – запрос в текущей строке, это ячейка
A2. - Таблица – ставим курсор в поле, переходим на второй лист, щёлкаем по букве колонки, в которой у нас фразы нашего сайта (колонка A, в данном случае); курсор при наведении на букву колонки принимает вид чёрной стрелки, направленной вниз.
- Номер_столбца – столбец с фразами нашего сайта, в данном случае, это столбец A, поэтому указываем
1. - Интервальный_просмотр – вбиваем
ЛОЖЬ(точный поиск совпадений).
Растягиваем данные на все строки – дважды щёлкаем на перекрестье, которое появляется при наведении курсора в нижний правый угол ячейки, с которой работаем:
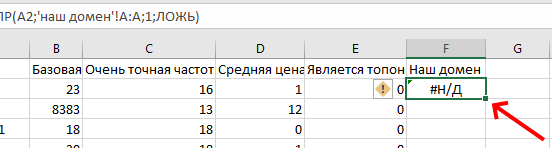
Так у нас получится значение от ВПР для каждой фразы из таблицы.
7.2.3.1. Статичные данные
Чтобы ускорить последующие операции (предотвратить пересчёт данных ВПР), нажимаем на букву столбца с данными ВПР, выделится весь столбец, нажимаем ctrl + c, затем выделяем ячейку заголовка столбца (F1 на снимке экрана), и используем кнопку вставки, выбрав вставку только значений:
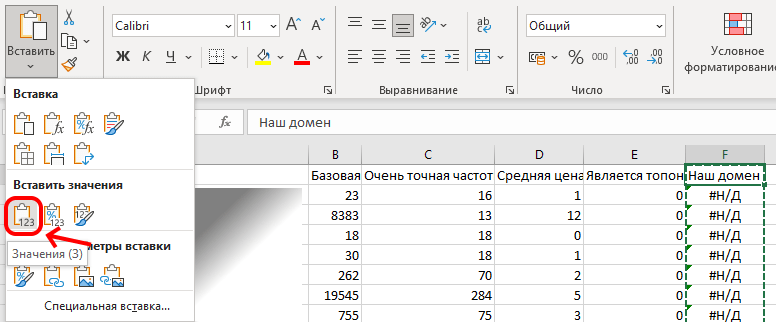
7.2.4. Удаление общих фраз
Значение #Н/Д в колонке ВПР свидетельствуют о том, что фраза есть у конкурентов, но отсутствует для нашего сайта.
Включаем фильтр по столбцам. Нам нужно очистить таблицу от строк, значение которых не #Н/Д в колонке данных ВПР.
Для этого надо либо отфильтровать столбец с данными ВПР по не #Н/Д и удалить строки, либо отфильтровать по #Н/Д и сделать на этой основе новую таблицу на этом же листе (напоминаю, работаем в открытом csv от Пингвина с добавленным листом).
7.2.5. Сохранение в csv для последующей обработки
Отключаем фильтры, удаляем колонку с данными ВПР, удаляем второй лист, где указаны фразы для нашего сайта, сохраняем csv и закрываем Эксель.
7.3. Удаление неявных дублей
Итак, у нас csv с данными по фразам, которые есть у конкурентов, но отсутствуют на нашем сайте. Однако, можно сократить объём данных, удалив неявные дубли фраз (такие фразы, где перемешан порядок следования слов в фразе).
Это можно было бы сделать ранее, на этапе первоначальной чистки (шаг 7.1), однако тогда мы получили бы неточную очистку от фраз, встречающихся для нашего сайта – некоторые неявные дубли могли бы встречаться в списке фраз нашего сайта, и они были бы удалены до сравнения с этим списком.
Чистку от неявных можно сделать либо только в Кейколлекторе, либо только в Пингвине, либо и там, и там – ниже рассмотрю именно такой подход.
7.3.1. В Пингвине
Открываем csv в Пингвине, выделяем столбец «Очень точная частотность» (цвет заголовка станет оранжевым), сортируем по убыванию частотности:
Выделяем столбец «Запрос», кликнув по его заголовку.
Выбираем удаление неявных дублей либо с учётом морфологии, либо без учёта. Я на данный момент предпочитаю чистку без морфологии:
Сохраняем результаты в csv.
7.3.2. В Кейколлекторе
Буду рассматривать КК 4-й версии.
7.3.2.1. Импорт
Импортируем csv в КК: файл – импорт – данные csv.
Если всё идёт в навалку в одном столбце, то в настройках импорта надо поменять точку с запятой на запятую, чтобы стало так:

Затем закрыть окно импорта, и снова начать импорт, чтобы оно появилось, но уже с корректным разделением на столбцы, для которых выбираем соответствия:

7.3.2.2. Непосредственно работа с неявными
Нажимаем кнопку «неявные дубли» на панели инструментов, и выставляем настройки (вроде бы это настройки по умолчанию):
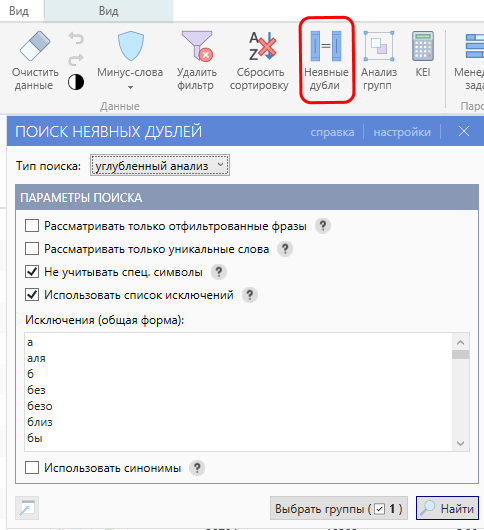
В результатах поиска неявных переходим в эти настройки:
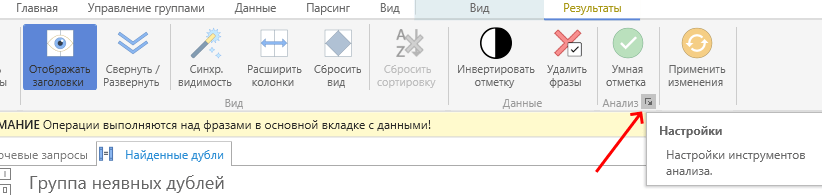
Выставляем такие параметры:
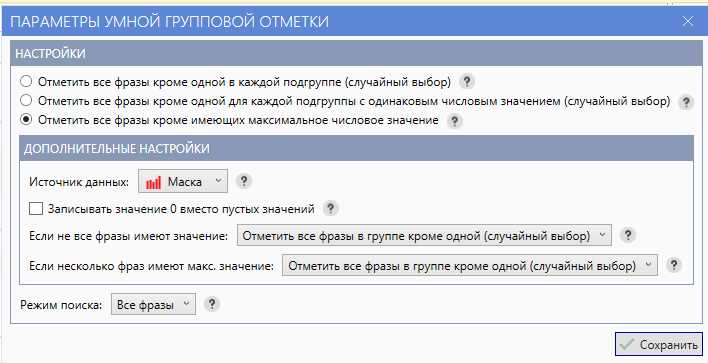
Нажимаем последовательно кнопки «Умная отметка», затем «применить изменения», затем «закрыть результаты».
Удаляем отмеченные строки.
7.4. Очистка от явного мусора
Такую очистку также можно провести либо в Пингвине, либо в Кейколлекторе.
Без фанатизма, вычищаем самый основной мусор, а не весь.
7.4.1. В КК
Если есть какой-то готовый список общих стоп-слов, то чистим с помощью него. Но тут внимательно – как и при любой чистке по стопам, можно потерять часть ценных фраз, если список стопов не совсем подходящий.
С помощью «анализа групп» (по отдельным словам) проходим часть списка, отмечаем, а затем удаляем.
7.4.2. В Пингвине
7.4.2.1. Стоп-слова
Также, как и в КК, можно провести первоначальную очистку с помощью списка стопов, вбив его в поле «Исключения». Есть поддержка регулярок и точных вхождений:

7.4.2.2. Кластеризация
Далее на вкладке кластеризации выбираем пресет «чистка»:
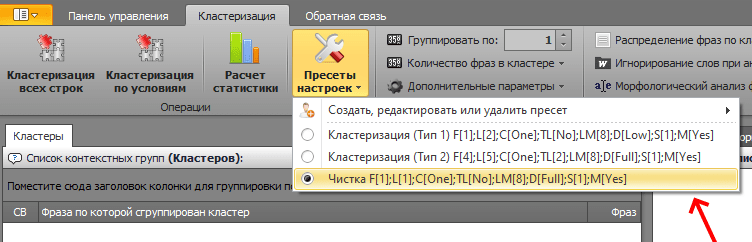
И нажимаем кнопку «кластеризация всех строк».
После кластеризации получится плоский список, по части которого проходимся и отмечаем мусорные для нас кластеры. Потом в контекстном меню выбираем следующее:
8. Кластеризация / группировка фраз
Группировка/кластеризация необходима, чтобы не перебирать весь список фраз. Качество кластеризации может хромать, главное, чтобы оно было неплохим – тогда будет некий перечень групп/кластеров, которые легче пробежать глазами, чем смотреть каждую фразу по-отдельности.
Опять же, здесь не преследуется цель расширить семантическое ядро новыми кластерами, а лишь понять направления расширения структуры сайта или увидеть проблемы с видимостью по структурным кластерам, уже присутствующем на нашем сайте.
8.1. По выдаче
Более удобной и чёткой считаю кластеризацию по выдаче (Keyassort, KK), но, возможно, кому-то вполне нормально будет работать с кластеризацией по составу фраз (Пингвин, КК).
Используем метод hard-4 или другой, если таковой показался более удобным для данной задачи.
В каждом случае, разумеется, работаем с экспортом/импортом данных, чтобы в итоге у нас была информация не только по кластерам, но и сопутствующие данные из Keys.so (частотности, цена клика и проч.).
Сам я снимаю поисковую выдачу в КК, а затем импортирую в Кейасорт (в два этапа) и там кластеризую, потом экспортирую в Эксель.
8.2. Ручная пост-обработка после кластеризации
Это видится бессмысленным, потому что трудоёмкая работа, польза от которой исчезающе мала для данного подхода.
Поэтому, какие кластеры программно получились, с теми и работаем.
9. Работа с итоговыми данными
Вручную разбираем получившуюся таблицу данных.