 admin
adminТак как раньше юзал Кей Коллектор, то после этих изменений постепенно появился запрос на его замену в части парсинга Вордстата. XWordstat Parser – тот софт, который можно использовать для сбора ключевых слов в качестве альтернативы.
1. X-Wordstat Parser
Софт, на котором остановил выбор. Позволяет парсить Яндекс Вордстат привычным образом: аккаунты Директа, прокси и антикапча.
Парсит разные виды частотностей (в том числе, маску), левую, правую колонки Wordstat’а, Директ – подскази и частотность (для добывания частотностей Вордстата через Direct).
Сохраняет результаты в CSV (можно импортировать в KeyCollector).
Где взять? Следите за обновлениями на https://x-parser.ru/ или пишите автору https://x-parser.ru/?do=feedback . Пока не было публичного релиза.
1.1. Скрины
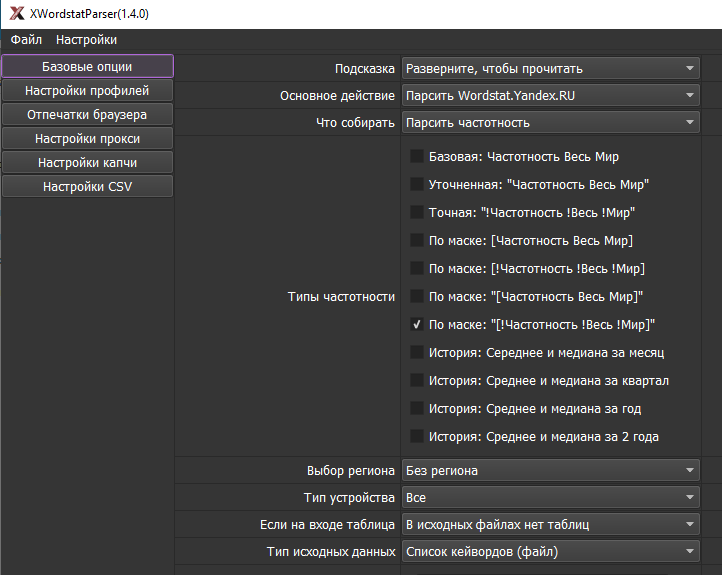
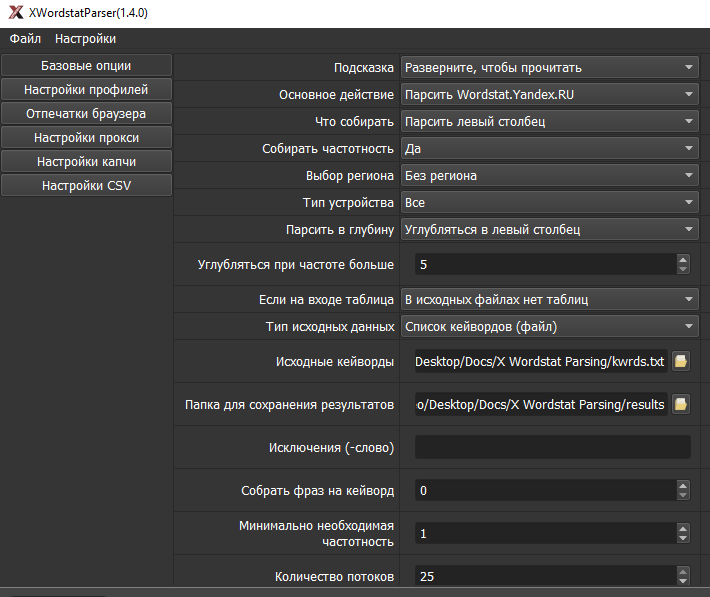

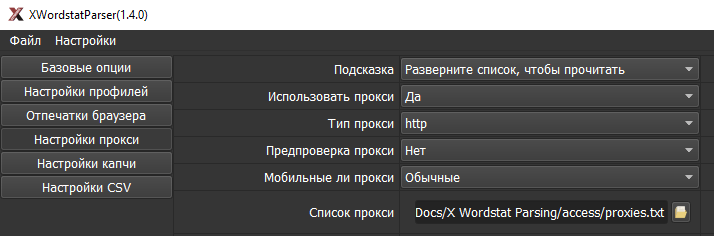
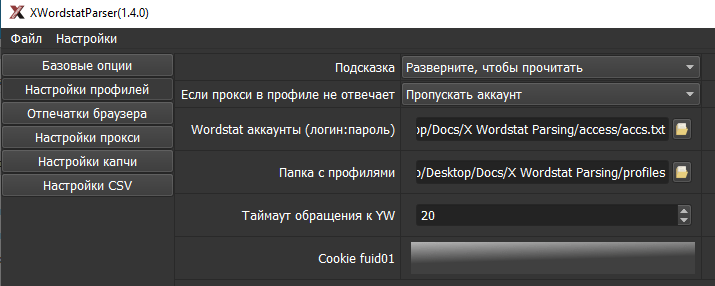
1.2. Отпечатки браузера
Парсер работает на BAS’е («эмулятор» браузера), вшиты отпечатки браузера по умолчанию. Не сталкивался с необходимостью докупать какие-то ещё.
1.3. Какие минусы
Столкнулся в работе с рядом неудобств, но думаю, разраб исправит позже (кроме п.2 – там в зависимости от реализации).
- У меня запускается только с правами админа.
- Парсинг Директа через браузер. Но тут двояко – привычен быстрый съём частот через КК в десятки потоков (там вроде без браузера). А здесь запускается по веб-браузеру на каждый поток. С другой стороны, если парсинг не по API Директа, тогда и вариантов других нет.
- Сохраняет без строки заголовков, приходится вручную её добавлять, чтобы импортировать в Key Collector.
- У меня Эксель всегда показывает кириллицу кракозябрами, надо открывать в Npp и перегонять в UTF-8 c BOM или ANSI, чтобы показывалось нормально.
2. Кей Коллектор
Парсинг Директа (для съёма частот фраз длиной до 7 слов) до сих пор вроде чётко работает. А для парсинга Вордстата были какие-то хаки с куками и прочим (в тг чате Кейколлектора об этом что-то упоминалось не раз), сам не испытывал, может что-то из того работает.
Сначала рассчитывал, что может будут исправления от разработчика, но после того, как написал в тикеты по поводу того, что у меня их софт падает при запуске на одном из компов, и не получил ответ за месяц, то предположил, что их техподдержка скорее мертва, чем жива. Справедливости ради отмечу, что данные по тикету не сохранил, видео с экрана не записывал, поэтому доказать произошедший казус я не могу, да и нет желания. Поэтому, можно считать, что мне всё это приснилось.
А вообще сам софт всё ещё в строю, разумеется – благодаря отсутствию сопоставимых аналогов по обработке табличных текстовых данных в разрезе работы с ключевыми фразами. Уж не знаю, сколько сотен (или тысяч) часов труда вложено в этот интерфейс, но я по-другому теперь на него смотрю – с тех пор, как стал писать кое-что по мелочи на C# (проверил на собственном опыте, что даже для реализации чего-то простого можно охренеть от того, насколько сложно это сделать).
3. Онлайн-сервисы
Этих сейчас как грязи. Их никогда не рассматривал, только если б наступило полное отчаяние. Не люблю я их, особенно, когда хочется разгуляться с парсингом. Некоторые хвалят за дешевизну XMLRiver, и сбор через этот сервис возможен и внутри КК, и внутри X-Wordstat Parser.