 admin
adminИногда полезно получить данные о количестве каких-то сущностей на продвигаемых страницах. Например, число товаров, число тех, которые не в наличии и т.д. (в основном, речь об ассортименте интернет-магазина).
Лучше всего эти сведения получать программным путём (выгрузка или какой-то дамп базы данных сайта). Но если нет, тогда может подойти и парсинг (например, с помощью Лягушки).
1. Варианты
Для получения данных Фрогом нужны экстракторы – CSS+XPath (см. п. 4) или CSS (см. п. 5).
Для примера рассмотрим подсчёт когтеточек для кошек здесь (не реклама!).
2. Селектор карточки каталога
Для подсчёта товаров требуется всего один экстрактор, указывающий на одну сущность, которую хотим сосчитать на странице. Так как считаем товары, то нужен экстрактор, указывающий на карточку товара в каталоге – например, подойдёт CSS селектор .product-item__main:
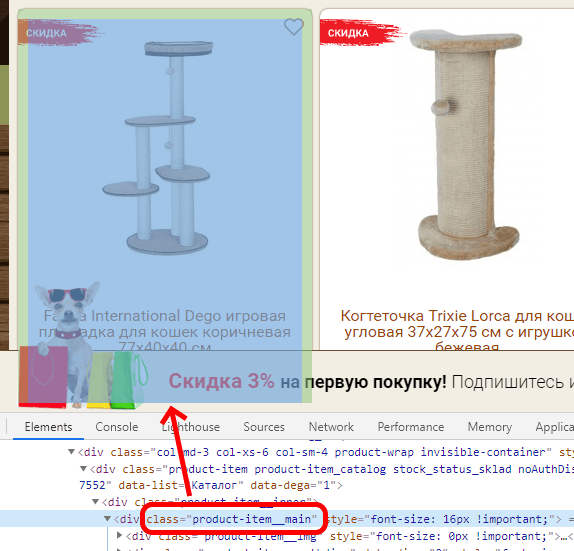
Проверить, что не захватываются какие-то лишние сущности DOM можно так (должно быть 4x6=24 карточки):
document.querySelectorAll('.product-item__main')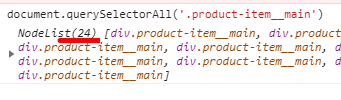
3. Страницы пагинации
В данном случае посчитаем и число страниц пагинации категории – для целостного представления об ассортименте.
Однако, для поиска ассортиментом является прежде всего то, что находится на одной странице. В данном случае, это первая страница пагинации – сама категория. Если пагинация была бы открыта для поиска (здесь она закрыта), то и тогда были бы большие сомнения, что поиск понимал бы реальный ассортимент.
3.1. Селектор для пагинации
Итак, вернёмся к извлечению данных о пагинации при парсинге.
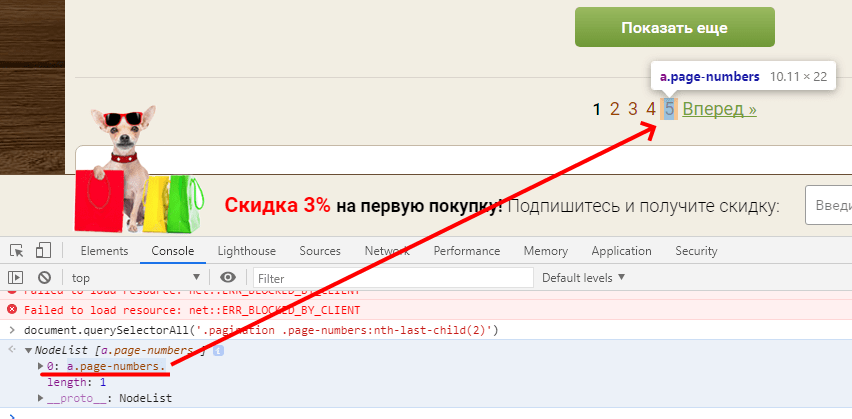
Можно выбрать селектор .pagination .page-numbers:nth-last-child(2), проверка такая (должен быть ровно один нужный элемент на странице):
4. Получение данных с использованием XPath
4.1. Пагинация
Про CSS-селектор пагинации понятно – будет извлечено для каждой категории число страниц пагинации, без необходимости какой-либо пост-обработки данных, поэтому используется подобранный ранее селектор в качестве экстрактора.
4.2. Число товаров
А для подсчёта сущностей карточек товаров в категории удобнее всего использовать функцию count XPath + конвертировать ранее подобранный CSS-селектор .product-item__main в XPath, получим: //*[@class='product-item__main']. Итого, готовый селектор XPath получится таким:
count(//*[@class='product-item__main'])4.3. Парсинг
Парсим Лягушкой с такими экстракторами/настройками:

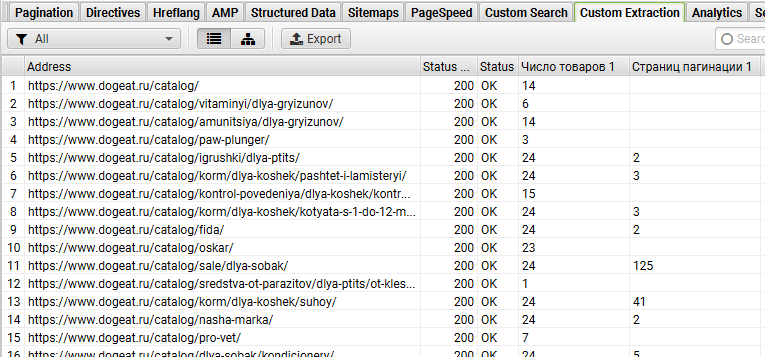
4.4. Результаты
После парсинга получаем данные по ассортименту:
5. Получение данных без использования XPath
Только при помощи подобранных ранее CSS селекторов. Это более муторный способ – предыдущий гораздо удобнее засчёт отсутствия необходимости пост-обработки данных по числу товаров.
5.1. Парсинг
Парсим Лягушкой с такими экстракторами:

Как ранее упоминалось, селектор пагинации обеспечит получение нужных данных без последующей обработки.
А для экстрактора карточки каталога обязательно нужно выставить атрибут – чтобы для всех карточек в экспорте было единое значение. Здесь выставлен класс, но можно и любой другой (если такой есть).
Таким образом, количество товаров в категории будет равно числу колонок, где встречается значение атрибута. Например, видно, что в категории https://www.dogeat.ru/catalog/kogtetochki/dlya-koshek/homecat/ есть только один товар:

5.2. Подсчёт встречаний в колонках
Теперь смысл затеи должен быть понятен – посчитать число колонок со значением product-item__main на каждом урле.
Наверняка это можно сделать более просто и красиво, но рассмотрю вариант с использованием такого скрипта Автоита. Итак:
- Скачать и установить оболочку;
-
Скачать основной код с Гитлаба (файл с расширением
.au3); -
Там же скачать файл настроек (
config.ini) и положить рядом с основным файлом скрипта; - В интерфейсе Лягушки на вкладке “Custom Extraction” нажать “Export” и сохранить в формате CSV в папку со скриптом, не меняя название файла;
-
Отредактировать в файле config.ini текстовый фрагмент экстрактора (для примера это
product-item__main). - Запустить скрипт, дождаться завершения – в файле results.csv будут данные.
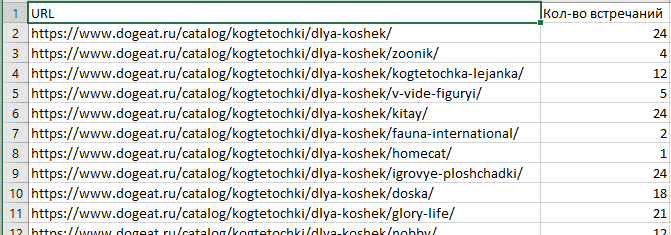
В рассматриваемом примере это выглядит где-то так (где количество встречаний и есть количество товарных карточек страницы категории):
5.3. Добавление данных о пагинации
Если мы экспортировали все экстракторы (Filter=All на вкладке Custom Extraction), то строки в файле results.csv совпадают со строками в файле экспорта Лягушки по всем экстракторам, и можно просто скопировать нужную колонку. Если нет, то свести данные с помощью Power Query.
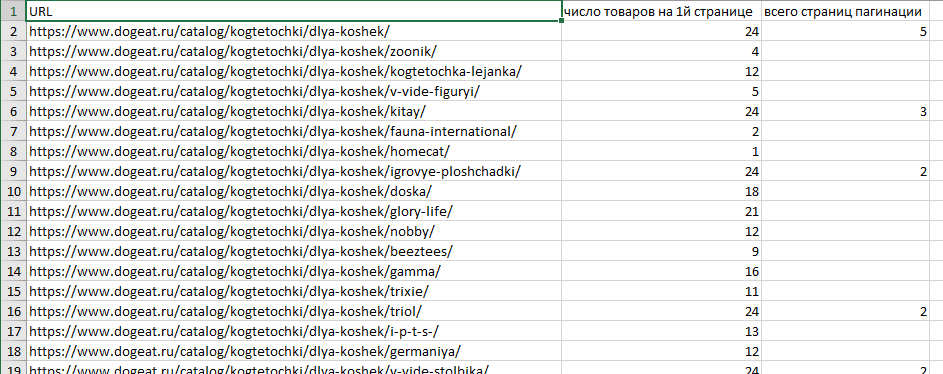
Итого должно получиться где-то так:
6. Применение
Поиск пустых категорий, с малым количеством товаров, поиск числа товаров не в наличии на первой странице пагинации, и т.д.